Managing Amazon Bedrock Cost: Pain Points and Solutions
Managing Amazon Bedrock Cost: Pain Points and Solutions
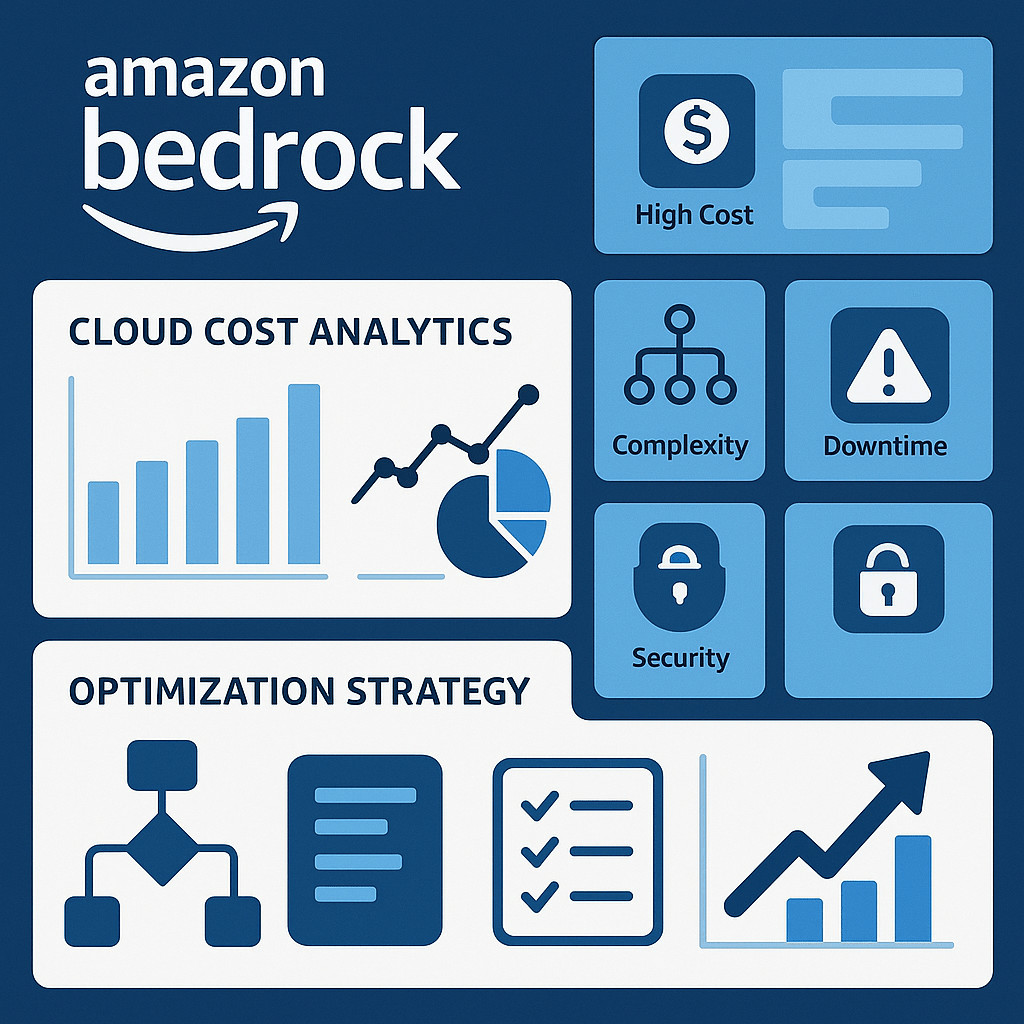
Cost management for Amazon Bedrock is top-of-mind for teams scaling generative AI. As usage grows, hidden expenses, unpredictable workloads, and complex pricing structures can quickly impact budgets. Here’s how to tackle key pain points—and win back control.
Common Cost Management Pain Points
1. Lack of Visibility:
Bedrock’s multi-layered pricing can make it hard to see exactly where budgets go. Without cost allocation tags and real-time tracking, teams miss the details and overspend.
2. Dynamic Usage Patterns:
Generative AI workloads vary by user demand, business needs, and model type. Sudden spikes or inconsistent usage can shatter forecasts and result in surprise charges.
3. Cost Structure Complexity:
Multiple pricing components—compute, storage, data transfer, training, and inference—are all managed separately. Each foundation model has its own pricing and rate structure, adding confusion for first-time users.
4. Multi-Tenancy & Cross-Team Spend:
In enterprise settings, different business units may share Bedrock resources. Tracking costs and aligning spend by team, product, or cost center is essential but can be difficult without the right tools.
Solutions and Optimization Strategies
Enable Cost Allocation Tags:
Assign AWS cost allocation tags to Bedrock resources. This lets you segment spend for agents, models, and endpoints by team, business unit, or project. Use AWS Budgets to set limits and trigger alerts for anomalies.
Monitor Workloads with CloudWatch and Cost Explorer:
Track token usage, model invocations, and service activity in real time. Set alarms for high token utilization or spikes in model usage. Use custom dashboards (QuickSight/third-party analytics) to visualize spend over time and by project.
Optimize Prompts and Batch Processing:
Design concise prompts to minimize token consumption. Use batch inference to process large datasets at lower rates, and avoid unnecessary on-demand spikes. Schedule batch jobs during off-peak hours.
Leverage Reserved Capacity and Autoscaling:
For steady workloads, purchase provisioned throughput with dedicated model units and longer commitments for greater discounts. Use auto-scaling to align resources with demand, scaling up only when truly needed.
Prompt Caching and Data Preprocessing:
Reuse prompt contexts through prompt caching APIs to save on both cost and latency. Clean and compress input data to reduce what’s processed, further lowering operational costs.
Regularly Review Model Selection and APIs:
Evaluate which models and configurations best match real business needs. Sometimes switching to a smaller or distilled model for common tasks nets significant savings.
Smart, proactive cost management ensures AI innovation on Bedrock stays efficient, forecastable, and scalable for every cloud team.



Responses