AWS Multimodal Video AI: Practical Ways to Unlock Your Video Content
AWS Multimodal Video AI: Practical Ways to Unlock Your Video Content
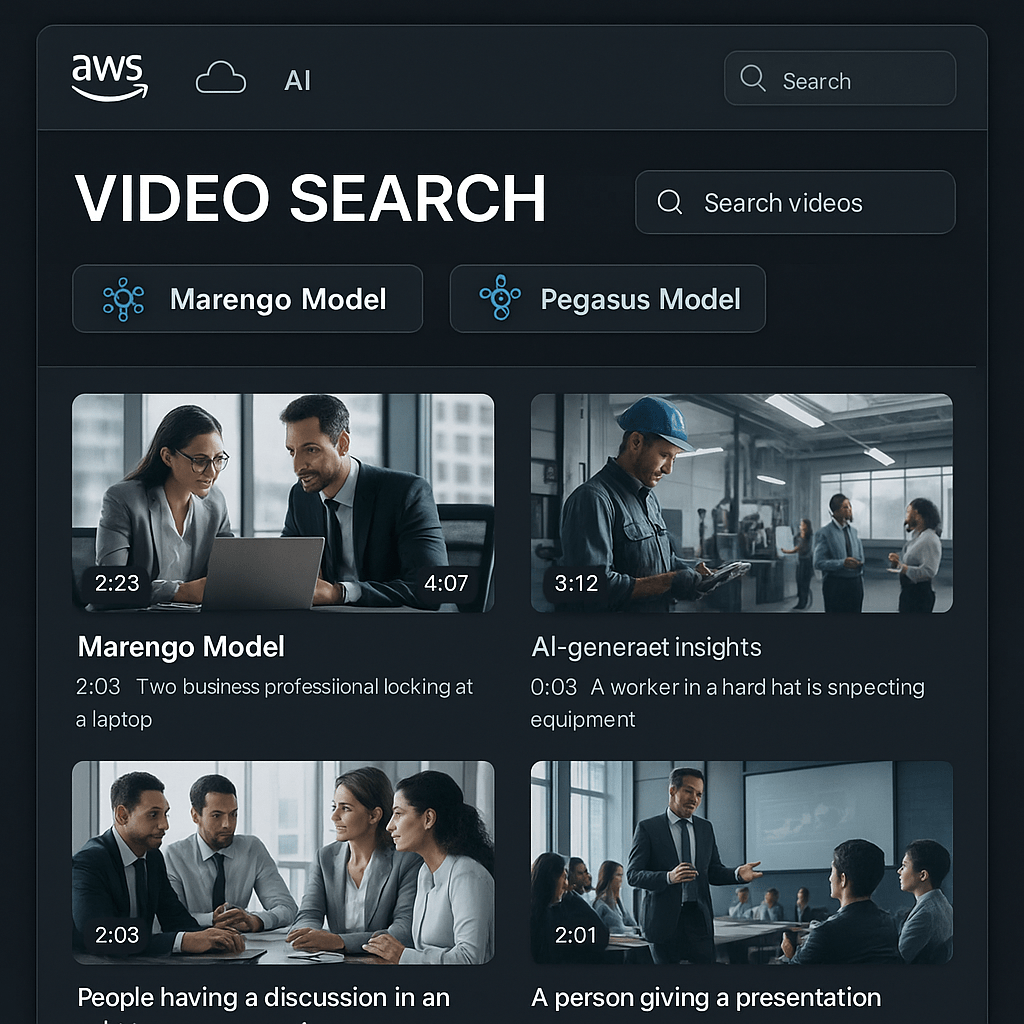
Video collections are everywhere, but finding, analyzing, and sharing key moments can be time-consuming. Recent AWS Bedrock integration with TwelveLabs’ Marengo and Pegasus models brings robust video AI capabilities to the cloud—making video content searchable and actionable without manual tagging or hours of review.
How does it help?
- Marengo transforms video into vector embeddings, allowing for rapid search and classification based on actions, objects, sounds, and story context—not just basic metadata.
- Pegasus generates readable summaries, chapters, and answers to everyday queries about video scenes, helping teams archive, review, and extract meaning from long-form footage faster.
Real-world applications:
- Pinpoint highlights (like a touchdown or an interview answer) in sports tapes, webinars, and customer interviews.
- Create searchable knowledge bases for large video repositories.
- Share summarized meetings or project updates with teams instantly.
Running this on AWS means secure, scalable access with compliance and easy integration into existing workflows.
Want to dive deeper? Check out these top tutorials and demo resources:
- End-to-End Video Understanding with Marengo & Pegasus on AWS Bedrock
- TwelveLabs Models in Amazon Bedrock Official Guide
- AWS Blog: TwelveLabs Video Understanding Models Now Available
- How Twelve Labs is unlocking video AI | Amazon Web Services – YouTube
- Multi-Vector Semantic Search with TwelveLabs on Amazon Bedrock – YouTube
What strategies have helped your team solve challenges in video analysis? Has anyone tested multimodal AI indexing or summarization yet?



Responses