Monitoring & Optimizing SageMaker Inference Costs: Practical Guide
Monitoring & Optimizing SageMaker Inference Costs: Practical Guide
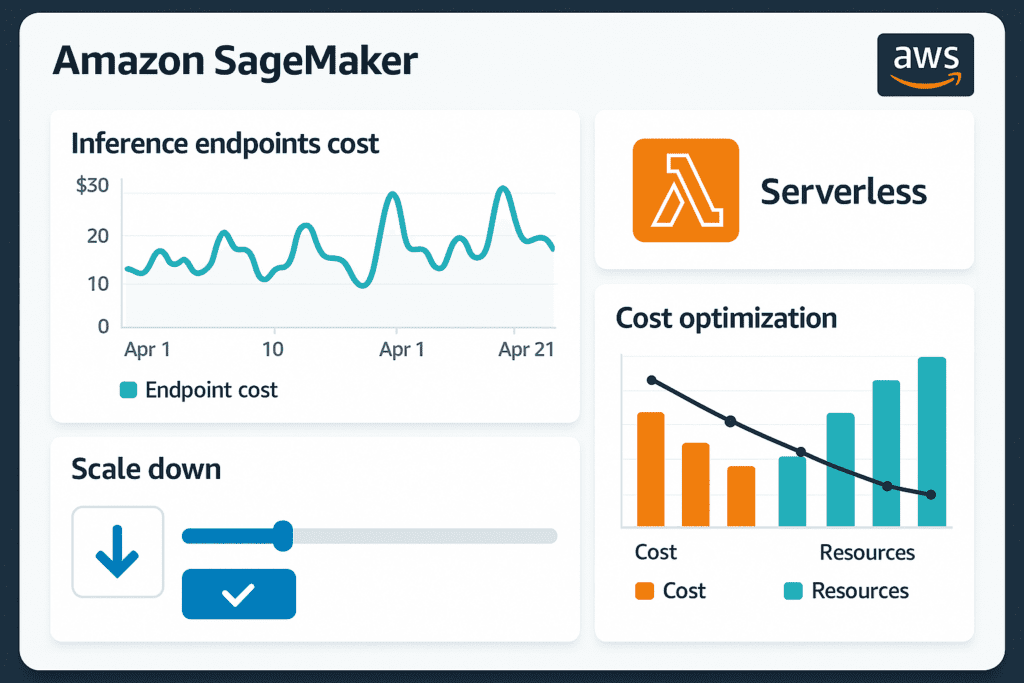
Inference can be the largest single cost for ML teams using Amazon SageMaker—so ongoing monitoring and optimization are crucial. From unpredictable demand to surprise bills, understanding cost drivers and using AWS’s tools effectively make a big difference.
Common Pain Points
- Always-on endpoints: Standard real-time inference keeps an instance running 24/7, even with low or unscheduled traffic, often leading to excess spend.
- Variable traffic: ML usage patterns fluctuate—temporary surges or quiet spells leave resources under- or over-utilized and budgets out of sync.
- Confusing pricing: Serverless, asynchronous, batch, and real-time options have separate cost structures. Lack of monitoring can lead to accidental overspending.
Cost Monitoring Features & Solutions
1. Use AWS Cost Explorer & CloudWatch
- Set up cost allocation tags to track per-project spending.
- Monitor endpoint hours, invocations, token usage, and data in/out with CloudWatch metrics.
- Build dashboards (QuickSight, third-party) to visualize historical and current spend across endpoints and workloads.
2. Rightsize & Switch Inference Types
- Move non-essential endpoints to serverless or asynchronous when traffic drops.
- For batch jobs, pay only for instance time used—not 24/7 hosting.
- SageMaker’s “scale to zero” feature lets endpoints automatically power down when idle, saving substantial costs for spiky or unpredictable traffic.
3. Savings Plans & Discounts
- Predictable workloads qualify for SageMaker Savings Plans, cutting hosting/inference costs up to 64%.
4. Use Multi-Model & Monitor Data Transfer
- Multi-model endpoints let you serve more models on the same instance, reducing underutilization.
- Don’t overlook charges for data input/output—optimize payload sizes and monitor transfer costs.
Action Steps
- Set alerts for cost anomalies or unusually high inference activity.
- Review cost per GB for input/output and optimize images, text, or payloads before sending.
- Tune auto-scaling policies and review instance types regularly.
- Align team workflows with inference options to balance performance and spend.
With the right monitoring and proactive adjustments, SageMaker inference becomes scalable and affordable for any ML-driven organization.
#AWS #SageMaker #CostOptimization #MLinference #CloudAI | improved by AI



Responses