How to Build Secure Agentic AI RAG Solutions
A lot of teams build agentic RAG the same way they build every other AI feature. They get retrieval working, connect a few tools, demo something impressive, and tell themselves security can come later. That feels efficient in the moment, but it creates a mess fast. By the time the system is useful, the agent already has access to documents, APIs, and workflows that were never designed with safe boundaries in mind.
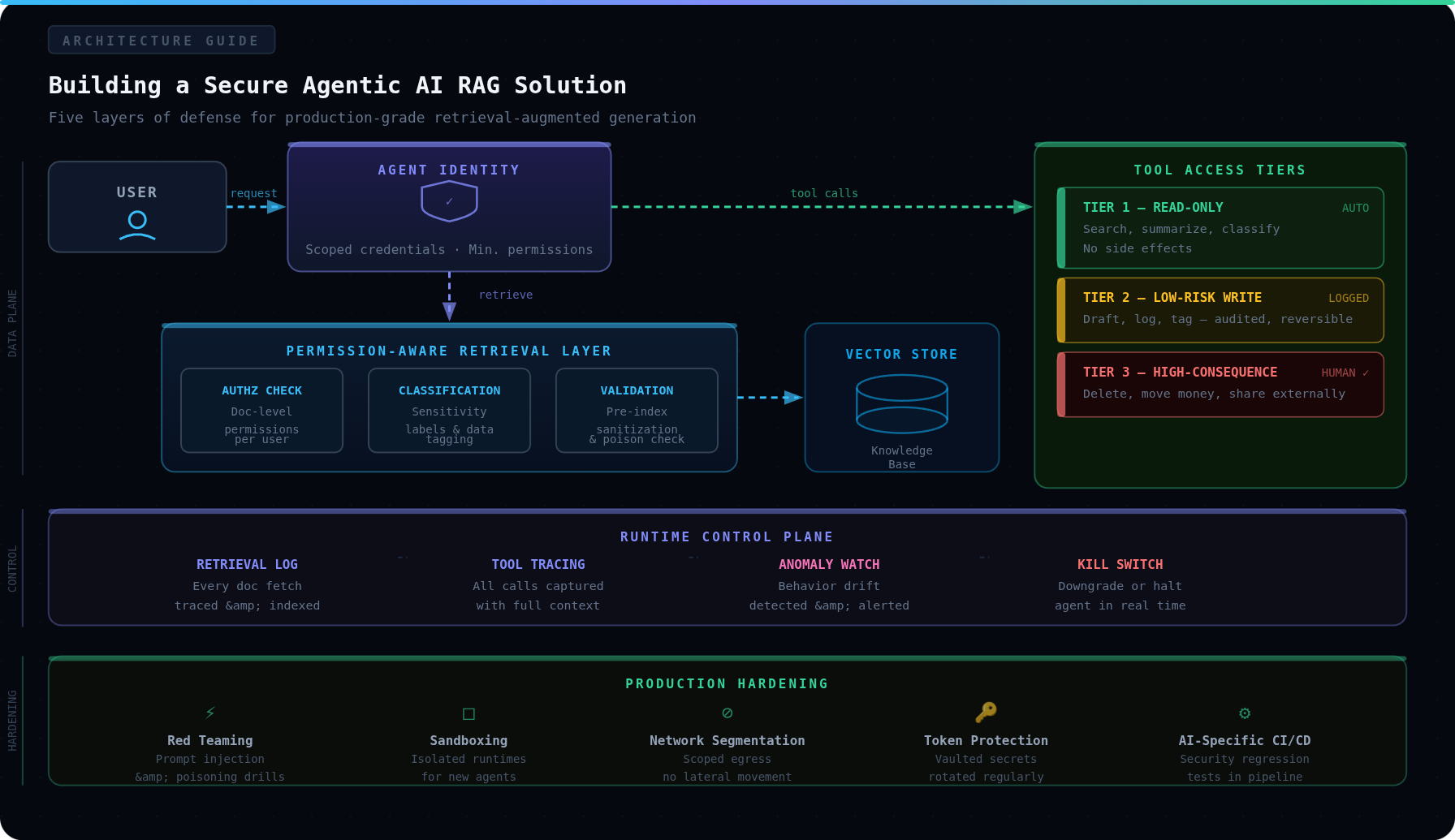
If you want to build a secure agentic AI RAG solution, the first thing to understand is that you are not building a chatbot with a better memory. You are building a non human identity that can retrieve sensitive information, reason over it, and decide what to do next. That means your security model has to cover four things from the start: who the agent is, what it can retrieve, what tools it can call, and what happens while it is running.
Start with identity
Most insecure agentic systems begin with a shortcut. A developer wires the agent to a shared service account, reuses an existing API key, or lets the agent act through a human user’s session because it is faster than setting up something cleaner. That shortcut is where the trouble starts.
Every agent should have its own identity. Not a shared secret sitting in a config file. Not a recycled token borrowed from another service. A real, unique identity that can be verified and tied back to a specific workload. That identity should have only the minimum access required for the job, and ideally it should receive just in time credentials with a short lifetime instead of standing privileges that never expire.
This matters because agents do not fail the way normal apps fail. A bad backend service might crash or return an error. An agent can keep going. It can retry, replan, and use the access you gave it in ways you did not predict. If it has broad standing permissions, it can do broad damage at machine speed.
A good rule is simple: if you cannot answer “which exact agent did this?” in your logs, your identity model is not good enough.
Make retrieval permission aware
This is where a lot of “secure AI” claims fall apart.
Teams will spend weeks tuning prompts and chunking strategies, then let the agent retrieve from a knowledge base that is far broader than what the end user should ever see. That creates a silent leak path. If the vector store can return documents the user is not authorized to access directly, the system is already broken.
Secure agentic RAG means access control has to exist at retrieval time, not after the answer is generated. Fine grained authorization should decide, at query time, which documents the user is allowed to see, and the vector search should be filtered before the model ever touches the content.
That sounds obvious, but a lot of systems still rely on broad application permissions and hope the model “does the right thing” with the content. It will not. The model cannot be your access control layer. Your retrieval pipeline has to enforce resource level permissions first, then retrieve only from the approved set.
There is a second piece here that matters just as much: ingestion. If you index poisoned documents, stale procedures, or sensitive files that were never meant to be searchable, the agent will reason over bad material as if it were trusted context. That is why secure RAG needs controls at ingestion, retrieval, and generation, not just one of those layers.
Treat tools like production change paths
The moment your agent can call tools, you have moved out of simple question answering and into operational risk.
A secure design does not treat all tools the same. Some are basically read only and low consequence. Others can change state, trigger workflows, message users, update tickets, or modify infrastructure. Those should never live under one flat permission model.
The cleanest way to think about this is by action tier:
Read only tools, like search, document lookup, or safe monitoring queries.
Low risk write tools, like adding comments, updating metadata, or drafting a response for approval.
High consequence tools, like deleting data, changing permissions, deploying code, or sending sensitive information outside the environment.
Once you separate tools this way, the controls get easier to design. Read only tools can often run automatically. Low risk writes may need stricter policy checks and better logs. High consequence actions should have explicit runtime gates, additional verification, or human approval before execution.
This is one of the biggest differences between a toy demo and a production system. A demo agent tries to prove it can act. A secure production agent proves it knows when not to.
Build runtime controls, not just setup controls
A lot of teams think security is handled once they configure the agent correctly. They lock down a few permissions, set up a vector database, maybe redact some inputs, and call it done.
But the real risk in agentic systems shows up during execution. Risk emerges while the agent is pulling context, interpreting instructions, chaining tool calls, and crossing boundaries between systems. That is why secure agentic AI needs runtime controls, not just static configuration.
At a minimum, that means:
Logging every retrieval event.
Tracing every tool call.
Distinguishing user actions from agent actions in your audit trail.
Watching for abnormal behavior, like an agent suddenly querying a new dataset or attempting a higher impact action path.
It also means building intervention points into the flow. You should be able to stop, downgrade, or require reapproval while the session is active, especially when the agent crosses into a more sensitive system or data domain.
This is where a lot of teams are still too optimistic. They assume that if the prompt is strong and the permissions are decent, the agent will stay in bounds. Maybe it will most of the time. But security is about the times it does not.
Keep secrets and credentials out of the blast radius
One of the sloppiest patterns in early agentic builds is credential handling. Static API keys wind up in environment variables, local configs, prompt traces, or logs because it is convenient. That is fine until your agent touches enough systems that one leaked secret turns into full lateral movement.
A more secure pattern is to use dynamic credentials with short lifetimes, issued only when the agent actually needs them and revoked when the task is done. That reduces the blast radius if the agent is manipulated or if its environment is compromised. It also forces better discipline around scoping, because you have to define what the agent is allowed to do in the first place.
Logging needs the same care. Good traces are essential, but careless traces can become their own security problem. Prompts, retrieved documents, tool payloads, tokens, and full embeddings should not all be dumped into a logging system just because “more telemetry is better.” Safe logging means capturing enough to investigate behavior without turning your audit pipeline into another leak path.
Design for failure, not just success
Secure agentic RAG is really about assuming the system will encounter bad inputs, bad documents, and bad situations.
Maybe someone poisons the corpus with malicious instructions. Maybe the user asks for something outside policy. Maybe a model takes a strange reasoning path and tries to use the wrong tool. Maybe a prompt injection buried in retrieved content tries to override the agent’s purpose. All of that has to be expected.
That is why production systems need more than happy path testing. They need red teaming against ingestion, retrieval, and tool use. They need sandboxing for new agents and constrained network paths for sensitive workflows. They need policies that are enforceable in code, not just written in a security wiki nobody reads.
A secure system should fail closed on high impact actions, not “do something reasonable” and hope for the best.
What secure agentic RAG actually looks like
In practice, a secure agentic AI RAG solution usually has a few clear traits.
The agent has a unique identity and does not hide behind a human session or shared credential. Retrieval is filtered with fine grained authorization before content ever reaches the model. Tool access is tiered by impact, and sensitive actions are gated with runtime policy or approval. Ingestion, retrieval, and generation all have security controls, because failure in any one layer can become a real incident. And the team operating the system can actually answer simple but critical questions: what the agent can access, what it did, why it did it, and how to stop it.
That is the bar. Not “the demo worked.” Not “the model seemed smart.” Not “we will add governance later.”
If an agent can retrieve sensitive data and act on systems, then it is part of your security boundary from day one. Build it like that.